Abstract
We present a neural radiance field method for urban-scale semantic and building-level instance segmentation from aerial images by lifting noisy 2D labels to 3D. This is a challenging problem due to two primary reasons. Firstly, objects in urban aerial images exhibit substantial variations in size, including buildings, cars, and roads, which pose a significant challenge for accurate 2D segmentation. Secondly, the 2D labels generated by existing segmentation methods suffer from the multi-view inconsistency problem, especially in the case of aerial images, where each image captures only a small portion of the entire scene. To overcome these limitations, we first introduce a scale-adaptive semantic label fusion strategy that enhances the segmentation of objects of varying sizes by combining labels predicted from different altitudes, harnessing the novel-view synthesis capabilities of NeRF. We then introduce a novel cross-view instance label grouping strategy based on the 3D scene representation to mitigate the multi-view inconsistency problem in the 2D instance labels. Furthermore, we exploit multi-view reconstructed depth priors to improve the geometric quality of the reconstructed radiance field, resulting in enhanced segmentation results. Experiments on multiple real-world urban-scale datasets demonstrate that our approach outperforms existing methods, highlighting its effectiveness.
Methodology
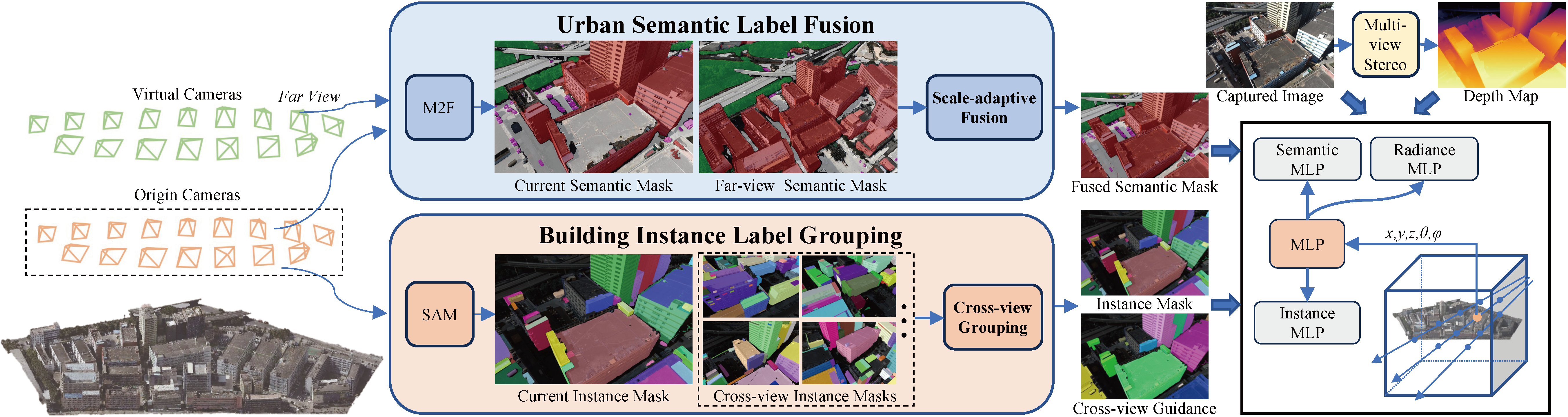
We present a neural radiance field (NeRF) method for urban-scale semantic and building-level instance segmentation from aerial images by lifting noisy 2D labels to 3D.
For semantic segmentation, we adopt a scale-adaptive semantic label fusion strategy to fuse the semantic labels from different altitudes using images rendered by NeRF, mitigating the ambiguities of the 2D semantic labels.
For instance segmentation, we propose a cross-view instance label grouping strategy to guide the training of instance field.
In addition, depth-prior from Multi-view Stereo (MVS) is introduced to enhance the geometry reconstruction, leading to more accurate semantic learning.